MongoDB 分片实战
背景
MongoDB自带了自动分片的功能,对集群进行分片,就可以把写请求定向到多个分片中,并发能力可以提高,并且当需要更强的并发时,可以通过加分片来实现。
MongoDB分片的概念并不难,分片只是简单的给一个集合指定一个片键。然而难点就是分配后有些操作不再合法,需要在分片后,在现有的系统上平滑过渡,不会引入新bug。
所以一开始要先去了解分片的原理,分片后会引入哪些限制,如何选择片键,哪些集合该分片,最后需要检查现有系统,确定某个集合分片后回对现有系统有什么影响。可以如何修改现有系统使得可以继续分片。
主体步骤
对一个集群进行分片,总结一下,有以下步骤:
- 了解分片的原理,只有知道分片是怎么运作的,我们才能知道如何对集合分片,如何选择片键;
- 了解片键的类型,这样才能知道我们应用适合哪些片键;
- 筛选出可以分片的集合,并且分析集合的访问模式,让请求尽量能路由到单一的片键;
- 分析现有代码,找到现在代码和分片后不兼容的地方,加以改正。
- 在测试集群上进行测试;
- 在正式集群上开始分片。
分片原理
分片是指将数据拆分,将其分散到不同的机器上的过程。
集群组件
了解分片,先得理解集群的组件,在一个主键中,主要有shard、mongos、config和客户端组成,如下图:
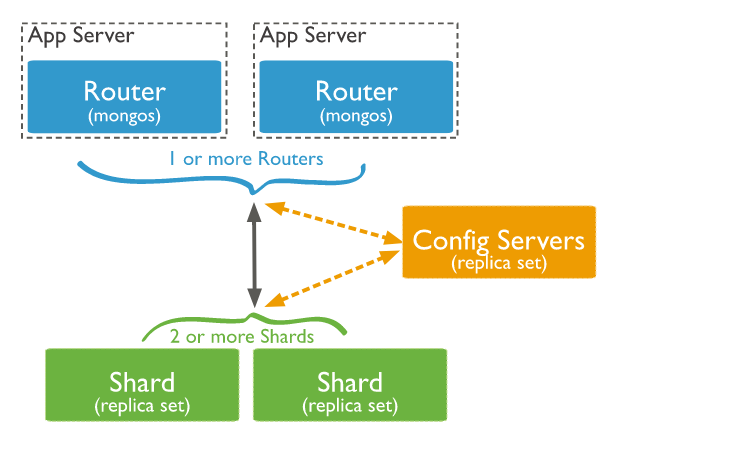
shard是一个分片,也是一个副本集,一般由一个primary和几个secondary组成,保存整个集群的一部分数据,提供故障时主从切换的功能。而一个集群通常含有多个shard。对于每个数据库来说,集群里有一个primary shard,这个分片保存了所有未分片的集合,每个数据库都有自己不同的primary shard。
mongos是一个router,我们的客户端通常不会直接连到shard,而是连接到mongos, 而mongos分析请求,将请求路由到一个或者多个shard,将结果组合起来,返回给客户端。
config其实是一个元数据服务器,保持了元数据,指示每个数据在哪个shard上,通常这是一个副本集。mongos连接到config获取元数据,根据元数据将客户端的请求路由到不同的shard。
所以在集群的主键上,和不分片相比,分片在客户端和服务器之间引入了一个中间层mongos,处理客户端请求,并且转发到不同的shard。
分片如何运行
了解分片组件后,我们来看看分片如何运行。MongoDB的分片是以集合为单位的,也就是把一个集合分布到多个shard上。分片最重要的是给集合选择一个片键。片键决定了集合的文档的分布。片键是一个索引域或者符合索引的域,并且每个文档都拥有。
MongoDB使用片键的区间来分区数据,将一个区间里的文档分布到特定的shard,每个区间片键都不重叠,并且和一个chunk相关。一个chunk的大小是64M,所以我们发现对于一些小集合分片就没什么必要性了。
MongoDB试图平均分配chunks,使得每个shard上的chunk的数量大体相同,所以片键和chunk分布的有效性相关性很大。
所以当mongos收到一个请求时,它会通过config服务器查询到和这个请求相关的chunk,以及这个chunk在哪个分片上,将请求路由到那个分片。
如以下集合,片键选择的是uid:
mongos> db.test_log.findOne();
{
"_id" : ObjectId("584e11890cf22b99df1c8f64"),
"mac" : "00-FF-2A-EC-B4-F7",
"os_bit" : 64,
"os_ver" : 601,
"uid" : "123456789",
"ver" : 111,
"ip" : "114.113.197.131",
"timestamp" : NumberLong("1481511305794"),
"timestamp_str" : "2016-12-12 10:55:05"
}
假设查询db.test_log.find({'uid': '123456789'}),这时候查询先发到mongos,mongos发现查询里有一个片键,根据从config拿来的元数据(一般都是缓存的)找寻出这个片键属于哪个chunk,并且在哪个shard,这样就直接把请求发到这个shard。
假设查询db.test_log.find({'ip': '114.113.197.131'}),这时候并没有片键存在查询中,mongos需要把请求重定向到所有shard中,汇总结果。
片键的类型和选择
片键的类型
片键有两种类型,一种是哈希,一种是区间。
区间片键,应该是最常用的,首先的,就是根据片键分成不同的区间,一个区间属于一个shard,如果一个字段的可以有很多种取值,并且相同的键出现得频率较低,而且片键不会逐渐增长,这个字段就非常适合做片键,区间片键可以很好的支持在片键上的范围查询,最优情况下,可以把请求路由到单一的shard。但是如果选择的片键逐渐增长,近期被插入的文档往往被写入同一个shard,造成写性能差,如果读更倾向于读近期的数据,读性能的扩展性也不好。
哈希片键,在一个具有哈希索引的字段上建立,它计算片键的哈希值,并且以哈希值的范围分成不同的区间,哈希片键的优势就是具有更平均的数据分布,片键逐渐增长不会影响数据分布。但是在哈希片键上做范围查询,需要把请求路由到所有机器。
片键的选择
知道片键的类型和分片的工作方式后,是时候来选择集合和片键了。
其实对于一个集合如何选择片键,最重要的是分析,在应用中如何使用这个集合,是经常在某个字段上做精确的查询,还是范围查询,其它字段上查询是否多等等。
对于
- 在某个字段上做精确的查询、或者范围查询;
- 并且这个字段的数据值很多,每个值的频率不高;
- 在其它字段上的查询较少;
- 并且文件在插入过程中,这个字段不会逐渐增长,或者减小。
满足以上条件,在这个字段上建立一个区间片键就是非常有效的。
对于
- 在某个字段上做精确查询,范围查询少;
- 并且这个字段的数据值很多,每个值的频率不高;
- 在其它字段上的查询较少;
- 这个字段逐渐增长,比如时间戳。
因为字段逐渐正常,不适合用区分片键,适合在这个字段上使用哈希片键。
片键的选择,其实就是根据访问模式,做一个权衡折中的抉择。选择什么,也会失去什么,就看哪个方案更加适合。
分片的限制
根据上面的内容,我们可以选出一些适合分片的集合,并且确定使用哪个片键,但是分片有一些限制,我们需要查看现有代码,看是否违反了这些限制,并且有什么方法可以修改代码。
根据官方文档,我总结了一下如下:
- 集合要指定一个片键,上面必须有索引,可以是复合索引,或者普通索引,如果是哈希片键,就必须是哈希索引,并且索引的增长是从小到大的;
- 使用
sort时,mongos传送$orderby选项,然后primary shard收到所有数据,进行归并排序,使用limit,会将limit传给每个shard,如果使用了skip,不能够将skip传给shard,所以需要把所有没有skip的内容都抓取回来再skip。如果skip和limit一起使用,可以都传给shard,来改善性能; - 插入文档时片键必须存在,也就是每个文档片键不能不存在,但是可以为
null; update时,如果multi=false, 查询必须包括_id或者片键,如果是upsert必须包括片键,同理save的文档也必须包括片键,findAndModify查询必须包含片键;remove如果指定justOne, 查询必须包括片键或者_id;unique只能是片键或者是包含片键作为前缀的复合索引;- 不能使用
group,$isolate$snapshot,geoSearch; - 片键一旦建立就不可改变,不能更新片键的值,也无法更换片键。
根据以上限制,我们需要检查现有代码看是否有违反这些规则的,然后进行修改。
开始分片
了解上面的知识后,我们可以先在测试服分片了,接下来的工作都是很简单的。
首先使用管理员账户进入mongo客户端,先开启对数据库的支持,如对test数据库开启分片支持:
sh.enableSharding("test");
然后对某一集合进行分片,如对test2分片,片键选择uid,这个索引是unique
sh.shardCollection("test.test2", {uid: 1}, unique=true);
在测试服测试完成后,就可以在正式服开始分片了,分片不需要停服,但是需要注意不要在线上环境使用的mongos上进行分片,因为如果对一个大集合分片,分片会卡主整个mongos,导致连接到这个mongos的请求都会被阻塞。
Balancer
在对一个集合分片后,Balancer会开始工作,将chunk从一个shard移到另外的shard,保持几个shard的chunk大致相同。
但是有可能出现chunk无法移动的情况,比如一个单一键的文档数量太多,都集中在一个chunk中,导致这个chunk过大,或者一个键太小,导致文档数据过多,这样的chunk会被标识成jumbo,不能移动到其它shard, 最后会导致数据分布不平衡。
对于这种情况,有时候需要停服改变片键,或者使用moveChunk手动移动chunk。
小结
- 本文介绍了分片的原理,片键的选择和分片的注意事项;
- 按照这些步骤仔细的开始分片,就可以达到平滑切换;
- 不过最好的体验就是分片的效果没有想象的好。